基本数据类型
map
map 中的 key 为什么是无序的
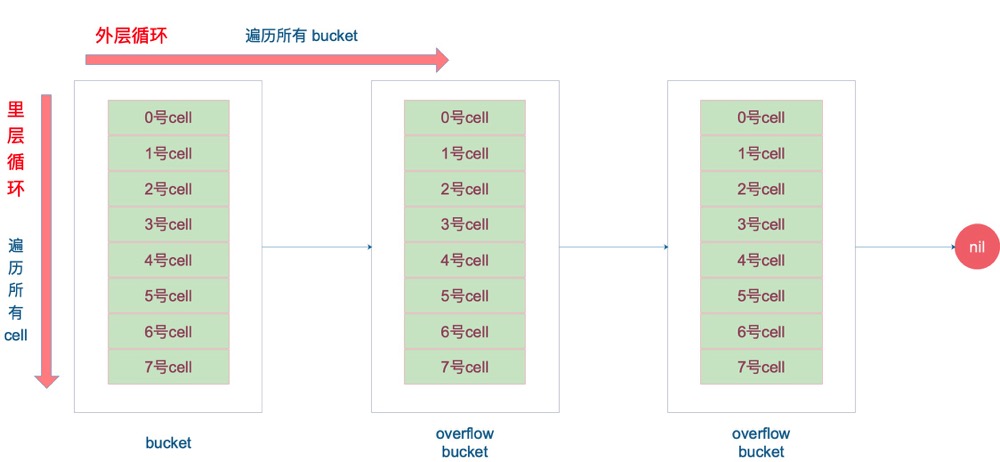
- map 在扩容后,会发生 key 的搬迁,原来落在同一个 bucket 中的 key,搬迁后,有些 key 就要远走高飞了(bucket 序号加上了 2^B)。而遍历的过程,就是按顺序遍历 bucket,同时按顺序遍历 bucket 中的 key。搬迁后,key 的位置发生了重大的变化,有些 key 飞上高枝,有些 key 则原地不动。这样,遍历 map 的结果就不可能按原来的顺序了。
- 当然,如果我就一个 hard code 的 map,我也不会向 map 进行插入删除的操作,按理说每次遍历这样的 map 都会返回一个固定顺序的 key/value 序列吧。的确是这样,但是 Go 杜绝了这种做法,因为这样会给新手程序员带来误解,以为这是一定会发生的事情,在某些情况下,可能会酿成大错。
- 当然,Go 做得更绝,当我们在遍历 map 时,并不是固定地从 0 号 bucket 开始遍历,每次都是从一个随机值序号的 bucket 开始遍历,并且是从这个 bucket 的一个随机序号的 cell 开始遍历。这样,即使你是一个写死的 map,仅仅只是遍历它,也不太可能会返回一个固定序列的 key/value 对了。
- “迭代 map 的结果是无序的”这个特性是从 go 1.0 开始加入的
map 是线程安全的吗
- map 不是线程安全的。
- 在查找、赋值、遍历、删除的过程中都会检测写标志,一旦发现写标志置位(等于 1),则直接 panic。赋值和删除函数在检测完写标志是复位之后,先将写标志位置位,才会进行之后的操作。
- 同时读写一个 map 是未定义的行为,如果被检测到,会直接 panic。
可以对 map 的元素取地址吗
- 无法对 map 的 key 或 value 进行取址,会 panic
- 如果通过其他 hack 的方式,例如 unsafe.Pointer 等获取到了 key 或 value 的地址,也不能长期持有,因为一旦发生扩容,key 和 value 的位置就会改变,之前保存的地址也就失效了。
map 的底层实现原理
Go 语言采用的是哈希查找表,并且使用链表解决哈希冲突
哈希冲突解决
-
开放寻址法
核心思想是依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中,如果发生了冲突,就会将键值对写入到下一个索引不为空的位置
-
拉链法
拉链法会使用链表数组作为哈希底层的数据结构
key 定位过程
下图中,假定 B = 5,所以 bucket 总数就是 2^5 = 32。首先计算出待查找 key 的哈希,使用低 5 位 00110,找到对应的 6 号 bucket,使用高 8 位 10010111,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
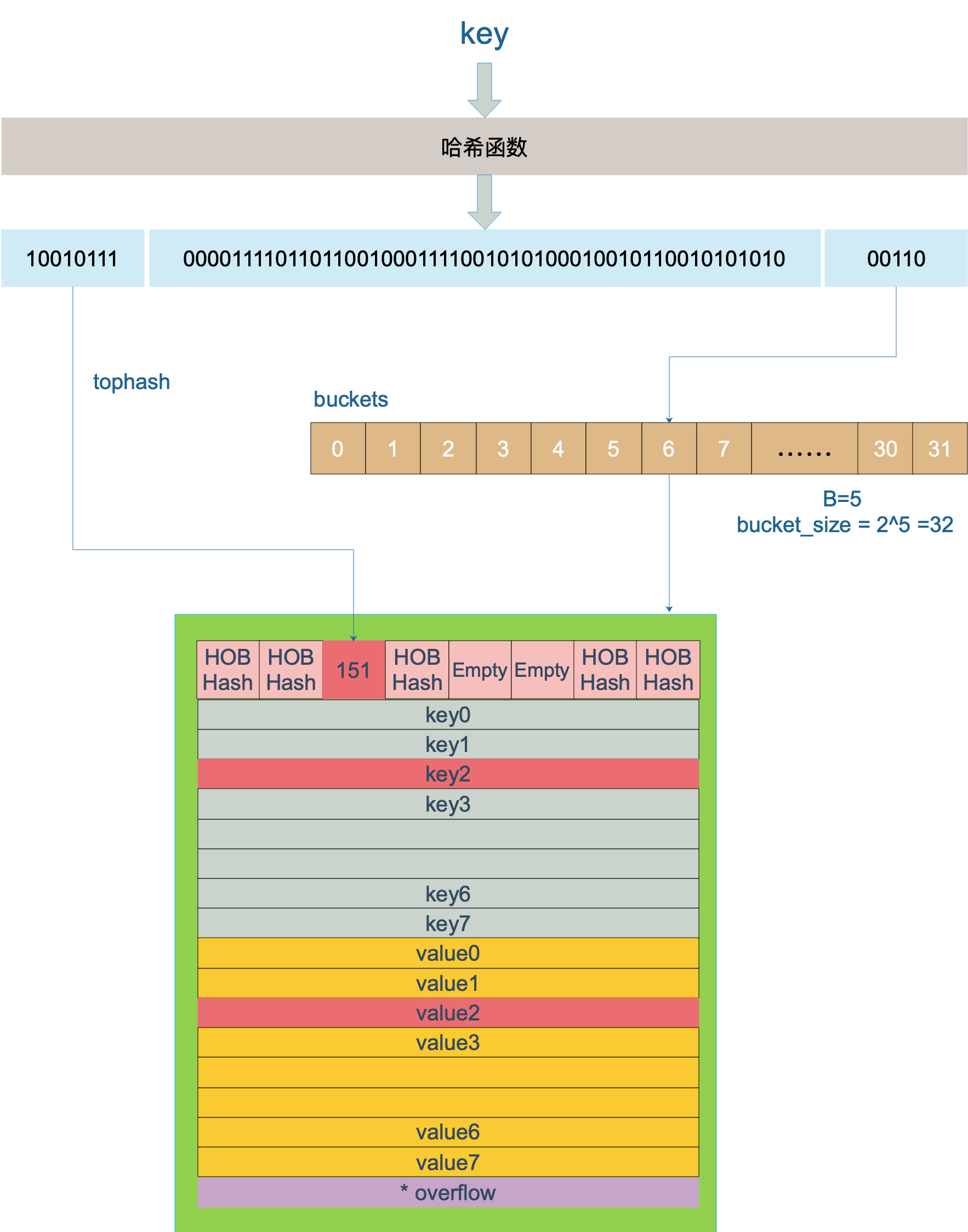 如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。